ABBA Document Classification
What is Abba Document Classification Platform?
ABBA is a domestic classification solution developed by DDI Technology R&D unit with the support of TUBITAK 1507. Regardless of the sector, it can be easily adapted to the solution of many classification problems. Labor is saved by automating manual processes. The entire digitalization process is completed in 5 times shorter time than the manual process. Errors related to the human factor in the classification process have been prevented.
BENEFITS

Errors due to human factor in the classification process are prevented

The entire digitization process was completed in 5 times shorter time than the manual process .
Labor savings were achieved by automating manual processes.

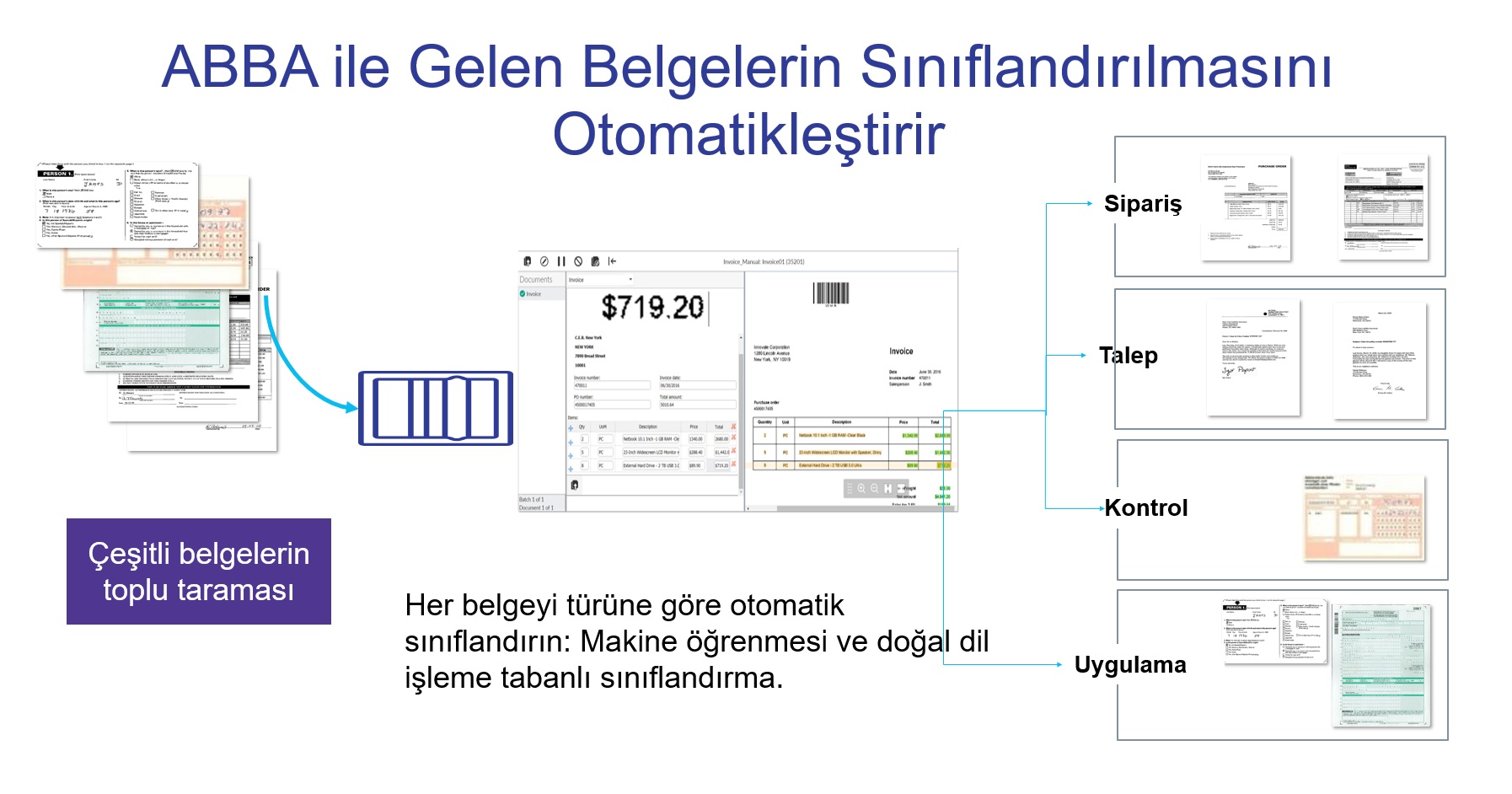
An Exemplary Success Story with ABBA.
Digitization of an institution's physical archive was carried out with ABBA. 3.500.000 pages of documents in the archive of the institution were scanned in bulk and transferred to the digital environment. ABBA analyzed the content of each page one by one, determined the class of the page with machine learning algorithms, and grouped the pages that should be together and performed the sorting process. The documents classified and sorted with ABBA were brought directly to the digital archive of the institution.

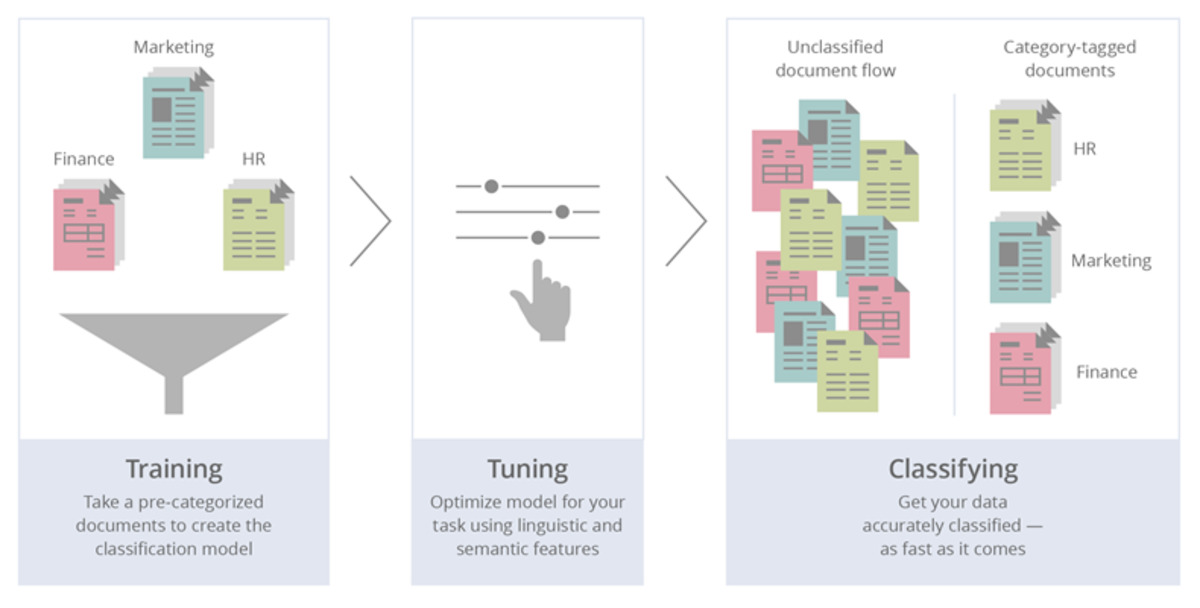
Working Phase
After the training phase is complete, ABBA is ready to work. The document or group of documents to be classified at the time of study is sent to ABBA. ABBA looks for the features it extracted from each page and sends these features to its classification algorithm. Then, the algorithm determines the most appropriate class information for the document and sends it to the system specified by the user.

Education Phase
The first step in adapting ABBA to a classification problem is training. During the training phase, ABBA is given sufficient number of paperwork samples for each class. At this stage, only the document itself and the class information are transmitted to the system. Apart from this, no feature extraction takes place. ABBA analyzes each given sample and automatically performs feature extraction for the classes. Finally, it creates a problem-specific classification algorithm with the features it has determined.
FEATURES
Natural language processing capability specially developed for Turkish language, which enables intelligent analysis of the text content of documents
OCR (Optical Character Recognition) feature for non-text content
Classification feature of a document according to both its content (text information) and figural appearance
Ability to be supported by rules in addition to machine learning methods
Intelligent classification with machine learning methods
GALERİ